Streaming Data¶
“流数据”是连续生成的数据,通常由某些外部源(如远程网站,测量设备或模拟器)生成。这种数据在金融时间序列,Web服务器日志,科学应用程序和许多其他情况下很常见。我们已经了解了如何在[实时数据](06-Live _Data.ipynb)用户指南中显示可调用的任何数据输出,我们还看到了如何使用HoloViews流系统在用户指南中推送事件部分[响应事件](11-响应_到Events.ipynb)和[自定义交互](12-Custom Interactivity.ipynb)。
本用户指南显示了使用DynamicMap和流构建交互式绘图的第三种方法。在这里,不是将绘图元数据(例如缩放范围,用户触发的事件,如“Tap”等)推送到DynamicMap回调,而是使用HoloViews直接更新可视化元素中的基础数据。 `Stream``。
特别是,我们将展示如何使用HoloViews的Pipe和Buffer流来处理流数据源,而无需从DynamicMap可调用内部获取或生成数据。除了简单地从“DynamicMap”外部设置元素数据之外,我们还将探索使用可选单独[streamz]协调的流数据处理方法
(http://matthewrocklin.com/blog/work/来自MattRocklin的2017/10/16/streaming-dataframes-1)
库可以使构建复杂的流媒体管道变得更加简单。
请注意,此页面演示了需要实时运行的Python服务器的功能。当导出到pyviz.org网站上的静态HTML页面时,您将只看到一个图。当将此代码作为Jupyter笔记本运行时,您应该逐个单元地执行它以依次查看每个操作的效果。
import time
import numpy as np
import pandas as pd
import holoviews as hv
from holoviews.streams import Pipe, Buffer
import streamz
import streamz.dataframe
hv.extension('bokeh')
Pipe¶
Pipe允许将数据推送到DynamicMap回调中以更改可视化,就像[响应事件](./ 11-Responding to Events.ipynb)用户指南中的流一样用于将更改推送到控制可视化的元数据。可以使用Pipe来推送任何类型的数据,并使其可用于DynamicMap回调。由于所有Element类型接受各种形式的data,我们可以使用Pipe通过DynamicMap将数据直接推送到Element的构造函数。
我们可以利用大多数元素可以在不提供任何数据的情况下实例化的事实,因此我们使用空列表声明Pipe并声明DynamicMap,将管道作为流提供,这将动态更新VectorField:
pipe = Pipe([])
vector_dmap = hv.DynamicMap(hv.VectorField, streams=[pipe])
vector_dmap.redim.range(x=(-1, 1), y=(-1, 1))
设置这个VectorField绑定到Pipe后,我们可以开始向它推送数据,改变VectorField的方向:
x,y = np.mgrid[-10:11,-10:11] * 0.1
sine_rings = np.sin(x**2+y**2)*np.pi+np.pi
exp_falloff = 1/np.exp((x**2+y**2)/8)
for i in np.linspace(0, 1, 25):
time.sleep(0.1)
pipe.send([x,y,sine_rings*i, exp_falloff])
这种直接使用元素构造函数的方法不允许您使用除默认键和值维之外的任何内容。这个限制的一个简单的解决方法是使用functools.partial,如下面控制长度部分中所示。
由于Pipe是完全通用的,数据可以是任何自定义类型,因此它提供了一种完整的通用机制来传输结构化或非结构化数据。由于这种普遍性,Pipe在使用下一节中描述的Buffer流时不提供一些更复杂的功能和优化。
Buffer¶
虽然Pipe提供了将任意数据传递给DynamicMap回调的通用解决方案,但另一方面Buffer提供了一种非常强大的方法来处理流表格数据,定义为pandas数据帧,数组,或列的词典(以及StreamingDataFrame,稍后我们将介绍)。 Buffer自动累积表格数据的最后一行N行,其中N由length定义。
累积数据的能力允许对最近的数据历史执行操作,而绘制后端(例如散景)可以通过仅发送最新的补丁来优化绘图更新。只有当Buffer持有的data对象与绘制的Element数据相同时,此优化才有效,否则所有数据都将正常更新。
一个简单的例子:布朗运动¶
要初始化Buffer,我们必须提供一个示例数据集,它定义我们将要流式传输的数据的列和dtypes。接下来,我们定义length以保留最后100行数据。如果数据是DataFrame,我们可以指定是否还要使用DataFrame````index。在这种情况下,我们将简单地定义我们想要绘制'x'和'y'位置的DataFrame和'count'作为Points和Curve元素:
example = pd.DataFrame({'x': [], 'y': [], 'count': []}, columns=['x', 'y', 'count'])
dfstream = Buffer(example, length=100, index=False)
curve_dmap = hv.DynamicMap(hv.Curve, streams=[dfstream])
point_dmap = hv.DynamicMap(hv.Points, streams=[dfstream])
应用了一些样式后,我们将显示动态“曲线”和“点”的“叠加”。
%%opts Points [color_index='count', xaxis=None, yaxis=None] (line_color='black', size=5)
%%opts Curve (line_width=1, color='black')
curve_dmap * point_dmap
现在我们已经设置了Buffer并定义了一个DynamicMap来绘制数据,我们可以开始向它推送数据。我们将定义一个简单的函数,通过累积x,y位置来模拟布朗运动。我们可以通过hv.streams.Buffer直接“发送”`数据。
def gen_brownian():
x, y, count = 0, 0, 0
while True:
x += np.random.randn()
y += np.random.randn()
count += 1
yield pd.DataFrame([(x, y, count)], columns=['x', 'y', 'count'])
brownian = gen_brownian()
for i in range(200):
dfstream.send(next(brownian))
最后,我们可以使用clear方法清除流和绘图上的数据:
#dfstream.clear()
使用Streamz库¶
现在我们已经发现了什么Pipe和Buffer可以做它的时间来展示如何将它们与streamz库一起使用。虽然HoloViews不依赖于streamz并且您可以使用流功能而无需了解streamz,但这两个库可以很好地协同工作,允许您构建管道来管理连续的数据流。 Streamz易于用于简单的任务,但也支持复杂的管道,涉及分支,连接,流量控制,反馈等。这里我们主要关注将streamz输出连接到Pipe然后Buffer以获得有关streamz API的更多细节,请参阅[streamz文档](https://streamz.readthedocs.io/en/最新/)。
将streamz.Stream和Pipe一起使用¶
让我们从一个相当简单的例子开始:
- 声明一个
streamz.Stream和一个Pipe对象,并将它们连接到一个我们可以推送数据的管道中。 - 使用20的
sliding_window,它将首先等待20组流更新累积。此时,对于每个后续更新,它将应用pd.concat将最近的20个更新组合到一个新的数据帧中。 - 使用
streamz.Stream上的sink方法来send得到20个更新为Pipe的集合。 - 声明一个
DynamicMap,它采用连接的DataFrames的滑动窗口,并使用Scatter元素显示它。 - 用“计数”对“散点图”点进行着色并设置范围,然后显示:
point_source = streamz.Stream()
pipe = Pipe(data=[])
point_source.sliding_window(20).map(pd.concat).sink(pipe.send) # Connect streamz to the Pipe
scatter_dmap = hv.DynamicMap(hv.Scatter, streams=[pipe])
设置完流媒体管道后,我们可以再次显示它:
%%opts Scatter [color_index='count', bgcolor='black']
scatter_dmap.redim.range(y=(-4, 4))
现在有一个管道,但最初这个图是空的,因为没有数据发送到它。要查看情节更新,让我们使用streamz.Stream的emit方法将小块随机大熊猫DataFrames发送到我们的情节:
for i in range(100):
df = pd.DataFrame({'x': np.random.rand(100), 'y': np.random.randn(100), 'count': i},
columns=['x', 'y', 'count'])
point_source.emit(df)
使用StreamingDataFrame和StreamingSeries¶
streamz库(版本0.2)提供了StreamingDataFrame和StreamingSeries,它是一种轻松处理表格数据实时源的有效方法。这使得它非常适合使用Buffer。 (在版本0.3streamz已经重命名了类来删除Streaming,所以这里的代码需要更新以用于后来的streamz版本。)使用StreamingDataFrame我们可以轻松传输数据,应用累积和滚动统计等计算,然后使用HoloViews可视化数据。
streamz.dataframe模块提供了一个Random实用程序,它生成一个StreamingDataFrame,它以指定的间隔发出一定频率的随机数据。 example属性让我们可以看到我们可以期待的数据的结构和dtypes:
simple_sdf = streamz.dataframe.Random(freq='10ms', interval='100ms')
print(simple_sdf.index)
simple_sdf.example.dtypes
由于StreamingDataFrame提供了类似pandas的API,我们可以直接指定对数据的操作。在这个例子中,我们减去一个固定的偏移,然后计算累积和,给我们一个随机漂移的时间序列。然后我们可以将这个数据帧的x值传递给HoloViews的Buffer并提供hv.Curve作为DynamicMap回调,将数据流式传输到HoloViewsCurve(带有默认键和值维度):
%%opts Curve [width=500 show_grid=True]
sdf1 = (simple_sdf-0.5).cumsum()
hv.DynamicMap(hv.Curve, streams=[Buffer(sdf1.x)])
Random StreamingDataFrame将异步发出事件,向前驱动可视化,直到它被显式停止,我们可以通过调用stop方法来做。
simple_sdf.stop()
使用StreamingDataFrame API¶
到目前为止,我们只计算了累积和,但是StreamingDataFrame实际上有一个广泛的API,可以让我们对我们的数据进行广泛的流式计算。例如,让我们将滚动均值应用于我们的x值,窗口为500毫秒,并将其叠加在“原始”数据之上:
source_df = streamz.dataframe.Random(freq='5ms', interval='100ms')
sdf2 = (source_df-0.5).cumsum()
sdf2.tail()
raw = hv.DynamicMap(hv.Curve, streams=[Buffer(sdf2.x)]).relabel('raw')
smooth = hv.DynamicMap(hv.Curve, streams=[Buffer(sdf2.x.rolling('500ms').mean())]).relabel('smooth')
raw * smooth.options(width=900,height=350)
source_df.stop()
对流数据的操作¶
正如我们在上面发现的那样,Buffer让我们设置一个length,它定义了我们想要累积的行数。我们可以利用这个优势并在此长度窗口上应用操作。在这个例子中,我们声明一个Dataset然后应用histogram操作来计算指定length窗口上的Histogram:
hist_source = streamz.dataframe.Random(freq='5ms', interval='100ms')
sdf4 = (hist_source-0.5).cumsum()
dmap = hv.DynamicMap(hv.Dataset, streams=[Buffer(sdf4.x, length=500)])
hv.operation.histogram(dmap, dimension='x')
hist_source.stop()
Datashading¶
同样的方法也适用于数据分析器操作,即使我们使它非常大(在这种情况下为100万个样本),也让我们对整个“长度”窗口进行数据分析:
%%opts RGB [width=600]
from holoviews.operation.datashader import datashade
from bokeh.palettes import Blues8
large_source = streamz.dataframe.Random(freq='100us', interval='200ms')
sdf5 = (large_source-0.5).cumsum()
dmap = hv.DynamicMap(hv.Curve, streams=[Buffer(sdf5.x, length=1000000)])
datashade(dmap, streams=[hv.streams.PlotSize], normalization='linear', cmap=Blues8)
large_source.stop()
使用tornadoIOLoop进行异步更新¶
在大多数情况下,您不希望在同一个Python进程中手动推送更新,而是希望对象在新数据到达时异步更新。由于Jupyter和Bokeh服务器都在[tornado](http://www.tornadoweb.org/en/stable/)上运行,我们可以在两种情况下使用tornado``IOLoop``来定义非阻塞协同例程这可以在数据准备就绪时将数据推送到我们的流中。
%%opts Curve [width=600]
from tornado.ioloop import PeriodicCallback
count = 0
buffer = Buffer(np.zeros((0, 2)), length=50)
def f():
global count
count += 1
buffer.send(np.array([[count, np.random.rand()]]))
cb = PeriodicCallback(f, 100)
cb.start()
hv.DynamicMap(hv.Curve, streams=[buffer]).redim.range(y=(0, 1))
cb.stop()
在这里,当您执行笔记本电脑时,图表应该像以前一样更新100次,但现在通过Tornado IOLoop不会阻止其他交互并在笔记本中工作。
真实的例子¶
使用Pipe和Buffer流我们可以非常容易地创建复杂的流图。除了我们在本指南中介绍的玩具示例之外,还有必要查看使用真实,实时,流数据的一些示例。
- [streaming psutil](http://holoviews.org/gallery/apps/bokeh/stream psutil.html)散景应用程序是一个这样的例子,使用
psutil`显示CPU和内存信息`library(用pip install psutil或conda install psutil``安装)
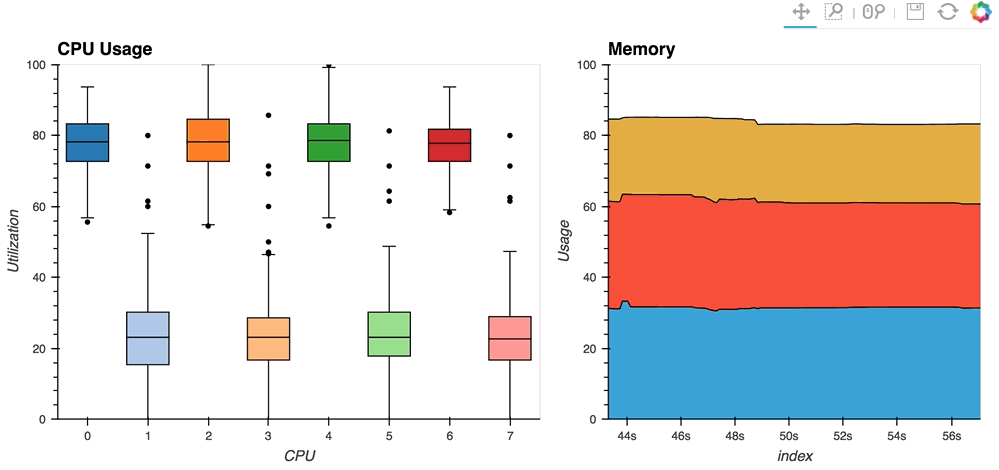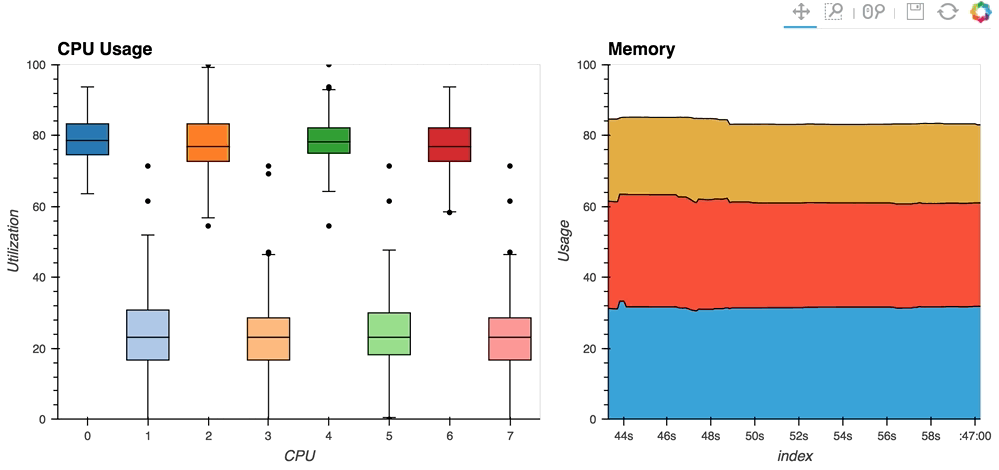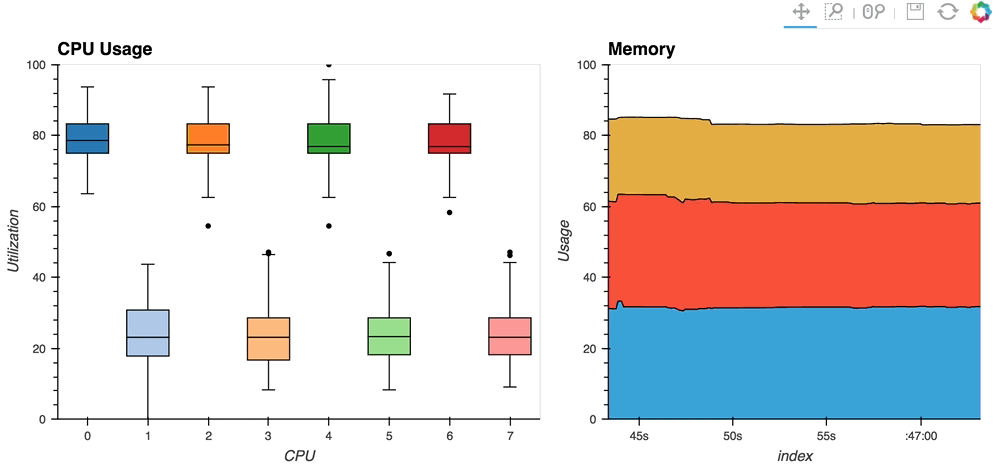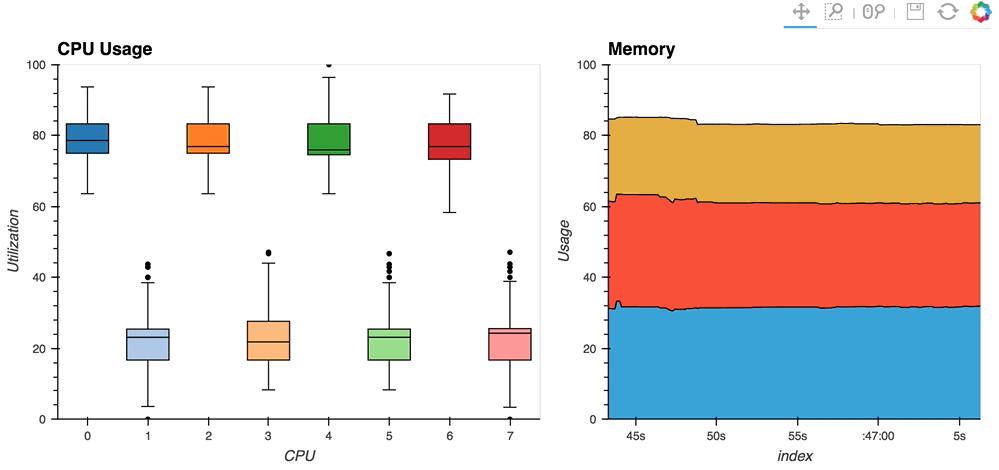
如您所见,流数据通常像HoloViews中的流一样工作,在显式控制下灵活处理随时间变化或由某些外部数据源控制。
本教程的最后几节将介绍如何将目前为止所涉及的所有概念纳入交互式Web应用程序以处理大型或小型数据集,首先介绍[参数和小部件](./ 12 <_>参数<_> and_Widgets.ipynb)。